System Prompts Don't Guarantee Tool Use
Same agent, same 'you MUST' instruction, five different tools. Only three got called.
TLDR: System prompts can say “you MUST use this tool.” The model only follows that when it can’t finish the task without calling the tool. If it can, it skips.
Agents pick which tools to call on every loop iteration. System prompts are supposed to constrain that choice. “Always classify first.” “Validate before responding.” “Log every query.” But the model treats these as suggestions, not rules. Some tools get called every time. Others get ignored completely, regardless of how the prompt is worded.
I tested five tools on the same research agent to figure out which ones get followed and which get skipped. The split wasn’t random.
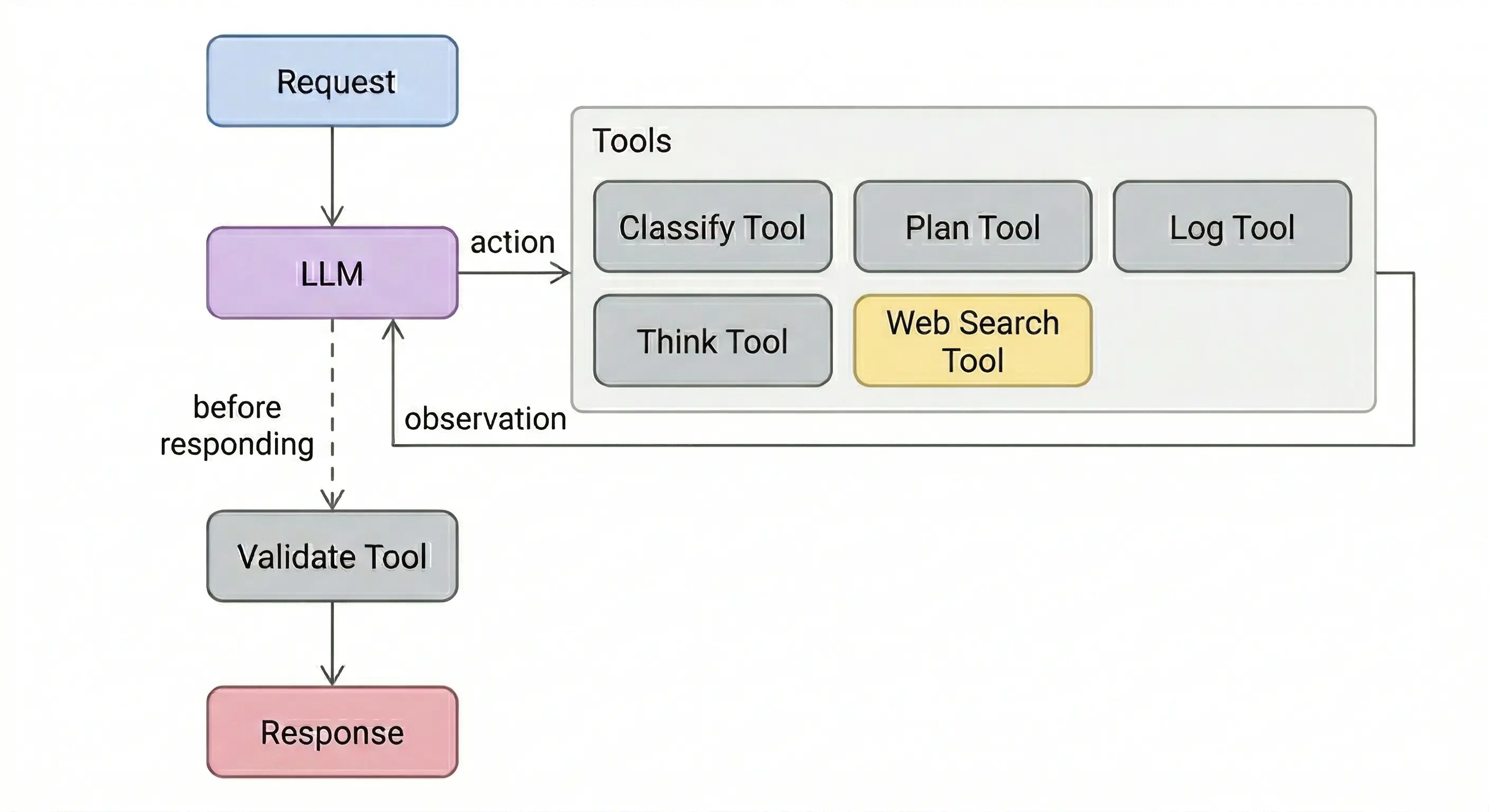
The Experiment
A research agent with a web search tool (Tavily). Five tools, each with a different job. Each experiment gives the agent one mandatory tool alongside web search, with a system prompt that explicitly says “you MUST use this tool.” Same task every time: compare two AI agent frameworks.
The five tools:
Classify takes the query, returns a category label like “framework comparison.” The model uses this label to decide how to search.
Plan takes the query, returns a list of sub-questions. The model uses these sub-questions to structure its searches.
Log takes the query, returns a confirmation ID. Audit trail for compliance. The model doesn’t need the ID for its task, but the prompt says log must run before search. The model can’t search without logging first.
Think takes the model’s reasoning so far, returns “Thought noted. Continue with your research.” A scratchpad. The return value adds nothing, and the model can search without it.
Validate takes the draft answer and sources, returns pass/fail with specific issues (missing citations, unsupported claims, hedge words). Runs after the model already has its answer, before it responds.
Each tool got its own system prompt. Every prompt used the same phrasing: “You MUST use [tool] before [searching / responding].” 10 runs per tool, on a smaller model and a larger one.
What Got Followed and What Got Skipped
| Tool | Prompt Says | Runs Before Main Action | Smaller Model | Larger Model |
|---|---|---|---|---|
| Classify | Before web search | Yes | 100% (10/10) | 100% (10/10) |
| Plan | Before web search | Yes | 100% (10/10) | 100% (10/10) |
| Log | Before web search | Yes | 100% (10/10) | 100% (10/10) |
| Think | Before web search | No | 0% (0/10) | 30% (3/10) |
| Validate | After web search | No | 100% (10/10) | 10% (1/10) |
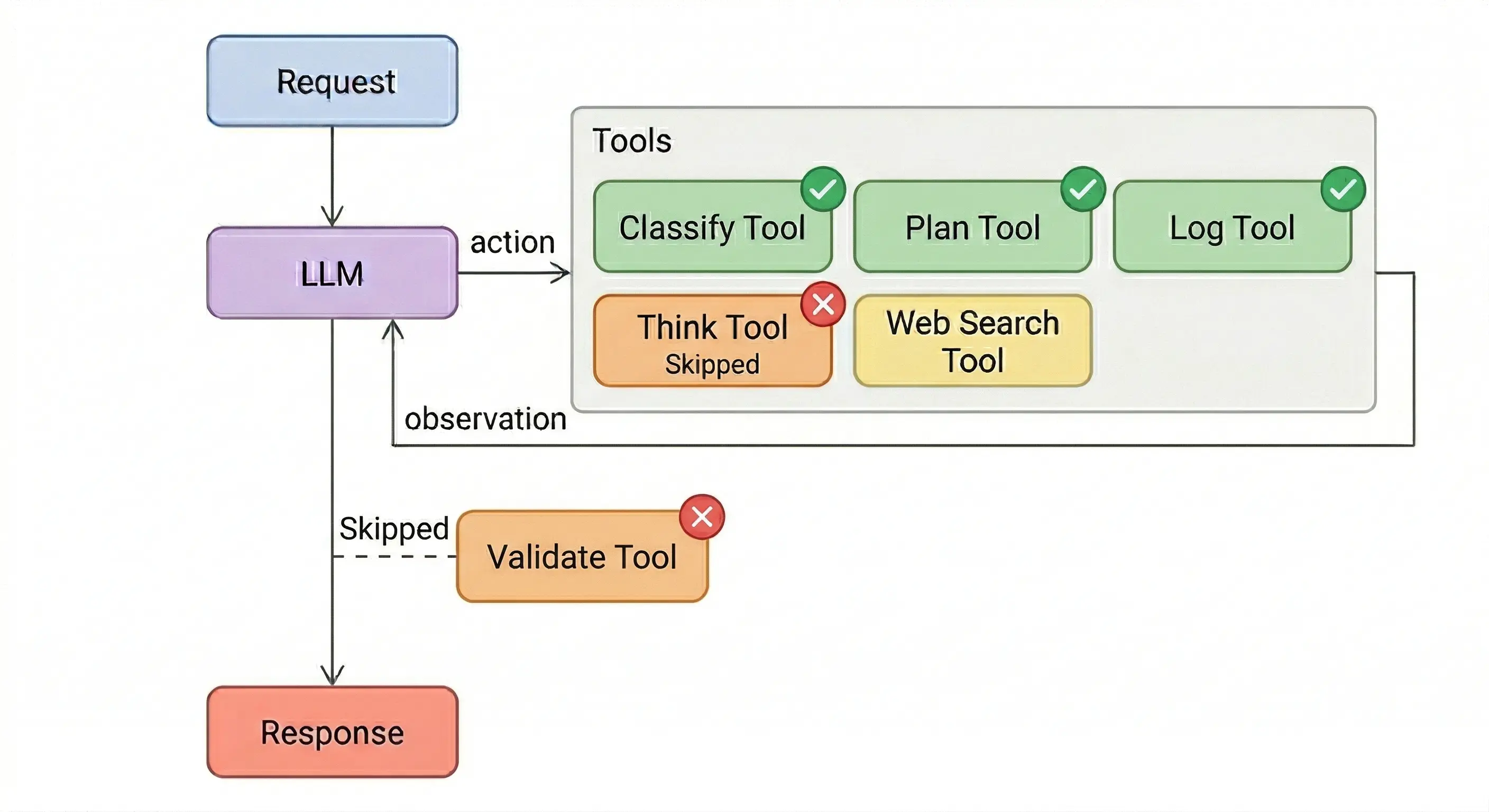
Classify, plan, and log all got 100% adherence on both models. The model can’t finish the task without calling them first. Classify shapes the search query. Plan structures what to search for. Log has to run before search is allowed.
Think got skipped almost entirely. The smaller model never called it once across 10 runs despite “Before EVERY search, you MUST use the think tool” in the system prompt. The larger model used it in 3 out of 10 runs. The prompt says to call it before searching, but the model can search without it. Skipping think doesn’t stop the task from finishing.
Validate is the interesting one. The smaller model followed it every run. Searched, validated, responded. The larger model skipped it 9 out of 10 times. Same system prompt, same tool, same task. It searched, had the answer, and responded without checking. No error, no crash. The output looked identical to a validated run.
The split isn’t about tool importance. Validate is arguably the most critical tool in the set. It catches bad answers. But by the time validate would run, the work is done. The model already has its answer and can respond without calling validate.
The larger model skips more because it’s more confident. It runs more searches (2.8 per run vs 1.0), builds a thorough answer, and decides the check is redundant. The stronger model is less compliant, not more.
Prompting Partially Fixes It
Adding few-shot examples changed the numbers. Instead of just telling the model to use think, the prompt included a complete workflow showing think being called before each search:
- Smaller model: 0% → 100%
- Larger model: 30% → 90%
The model didn’t skip because the instruction was unclear. It skipped because it had no pattern for calling a tool it can work without. Once shown how, the smaller model followed it perfectly. The larger model still skipped 1 in 10.
Better prompting moves the needle. It doesn’t close the gap. A 10% skip rate on a compliance or safety check is still a production problem.
Moving Tools Out of the Toolbox
The system prompt says “must.” The model evaluates whether it needs the tool’s output to continue. If it doesn’t, the instruction gets dropped.
Stronger wording won’t fix this. Few-shot examples won’t fully fix it either. If a step must always happen, it can’t be a tool the model chooses to call.
In LangGraph, validation can be a node instead of a tool. A step that runs unconditionally between the last tool call and the response:
def validate_node(state: MessagesState):
last_message = state['messages'][-1].content
result = validate_answer.invoke({'answer': last_message, 'sources': last_message})
return {'messages': [HumanMessage(content=result)]}
builder = StateGraph(MessagesState)
builder.add_node('llm', llm_node)
builder.add_node('tools', ToolNode(tools_list))
builder.add_node('validate', validate_node)
builder.add_edge(START, 'llm')
builder.add_conditional_edges('llm', tools_condition)
builder.add_edge('tools', 'llm')
builder.add_edge('llm', 'validate')
builder.add_edge('validate', END)
graph = builder.compile()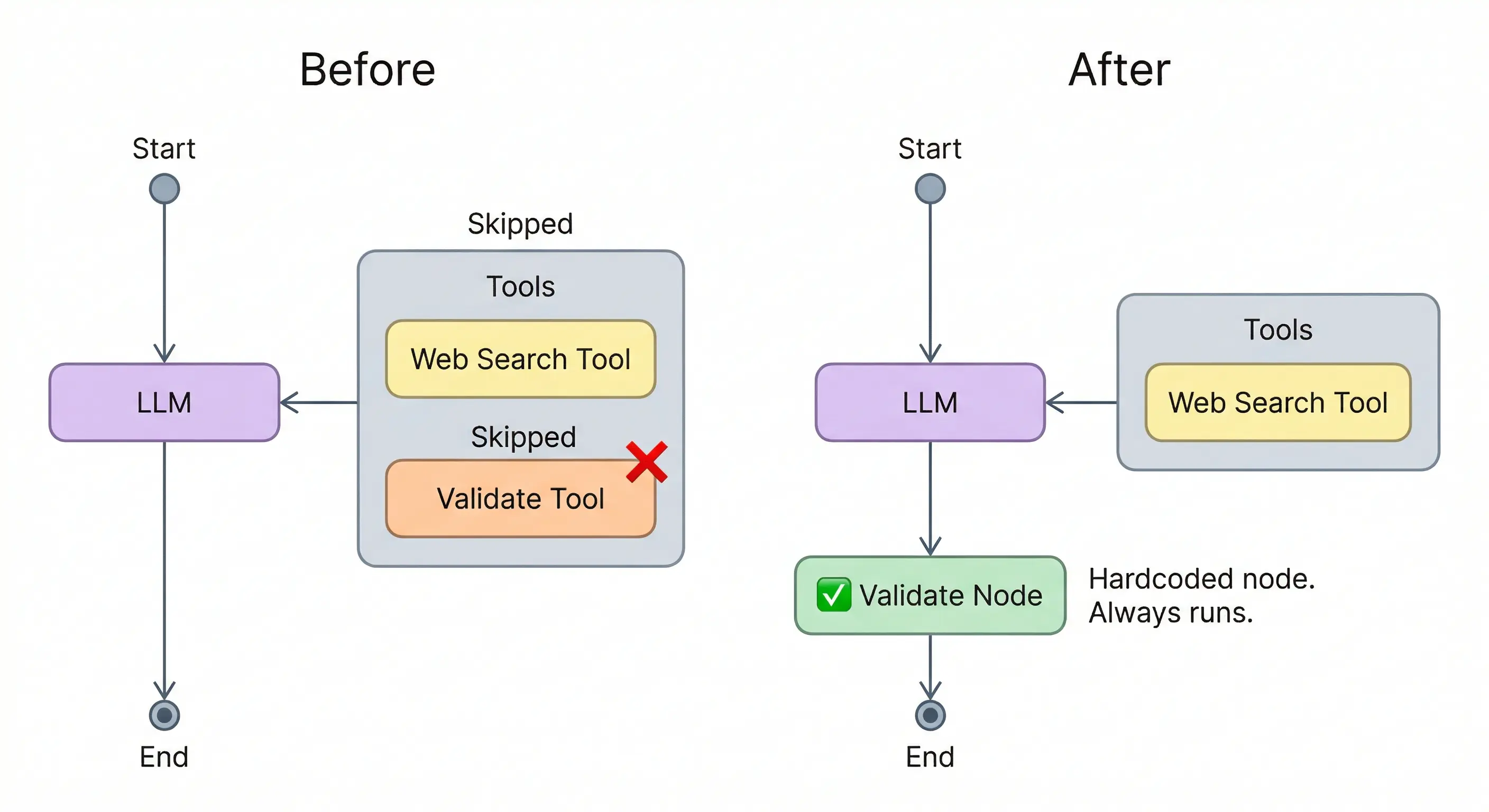
The model never sees this node as a tool. It’s part of the graph. Same principle applies to logging, PII redaction, or anything else that can’t be optional. Frameworks like Guardrails AI package this as middleware.
If a step must always happen, it doesn’t belong in the agent’s toolbox. It belongs in the graph.
Smaller model: Gemini 3.1 Flash Lite. Larger model: Gemini 3 Flash. LangGraph. 10 runs per experiment. Results will vary by model. The skip patterns won’t. Code: GitHub