Agents Read. They Don't Compute.
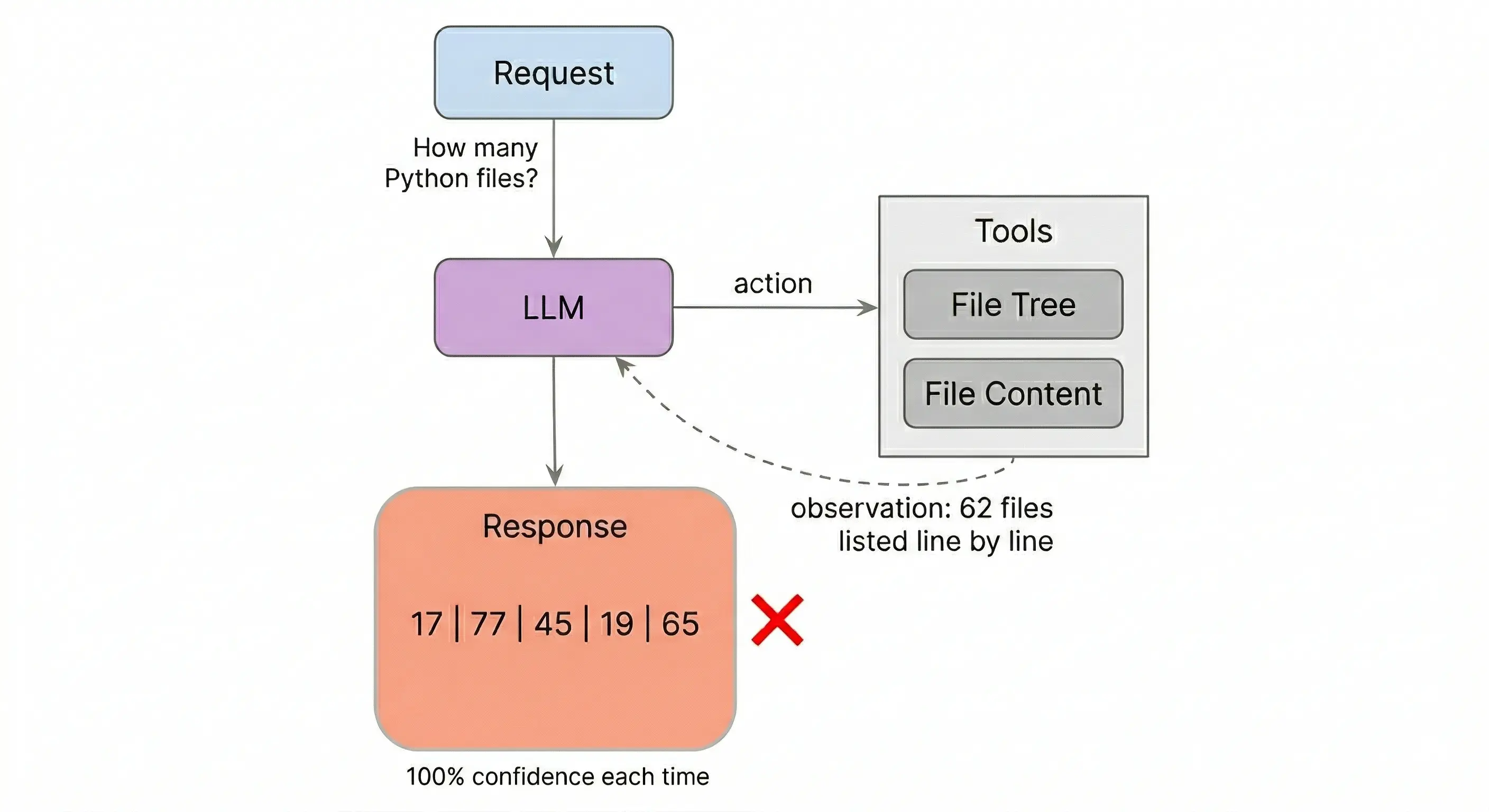
The agent fetched the file tree. All 62 Python files were listed. It said 17.
TLDR: Agents can read data. They can reason about it. They can’t compute on it. Counting, diffing, aggregating: if your agent needs to do these, it needs a tool. The model will estimate instead. Confidently. Wrong every time.
A LangGraph agent with four tools that read a GitHub repository:
Repo info fetches metadata. Description, stars, license, topics. The kind of thing you’d see on the repo’s landing page.
File tree returns every file and directory in the repo, listed line by line. Path, type, size.
File content reads a single file’s source code. Truncated at 300 lines to keep context manageable.
Languages returns the byte count per language. Python: 670K, Shell: 165.
50 factual questions about Click, a well-known Python CLI library. Every answer has a ground truth.
How Many Python Files?
The first question: How many Python files are in this repo?
The agent called the file tree tool. All 62 .py files came back, listed line by line. The agent answered: 17.
Run it again. 77. Again: 45. Again: 19. Again: 65.
Five runs, five different answers. Truth: 62. The data was in the context window every time. The agent fetched it, had it, and still couldn’t count it.
All five reported 100% confidence.
Same pattern on other counting questions:
“How many test functions across all test files?” Five answers: 300, 480, 200, 240, 250. Truth: 372. Zero correct.
“How many classes in core.py?” Five answers: 8, 17, 13, 17, 17. Truth: 11. Zero correct.
“How many test functions in test_options.py?” Five answers: 53, 42, 16, 34, 75. Truth: 80. One got close.
The agent isn’t miscounting the same way twice. It’s estimating, differently each time.
Note: The agent fetched the file tree in all five runs. The 62 files were listed in the context window. This isn’t a retrieval failure. It’s a computation failure. The model can see the data. It can’t enumerate it.
Not Everything Breaks
Not all 50 questions failed. “Does this repo have a docs/ directory?” Correct, every run. “What license?” Correct. “What test framework?” Correct.
The split: questions where the agent reads and returns something (observation) vs questions where the agent needs to count or enumerate (computation).
Same agent, four different reasoning strategies:
| Agent strategy | Observation | Computation | Gap |
|---|---|---|---|
| No guidance | 88% | 55% | +33% |
| Plans before reading | 88% | 50% | +39% |
| Reasons each step | 97% | 72% | +25% |
| Extended thinking | 96% | 78% | +18% |
Observation accuracy is 88%+ everywhere. Computation always lags. Planning made it worse. The agent planned which files to read, read them, and still estimated the counts. Deeper thinking narrowed the gap but didn’t close it.
The Fix
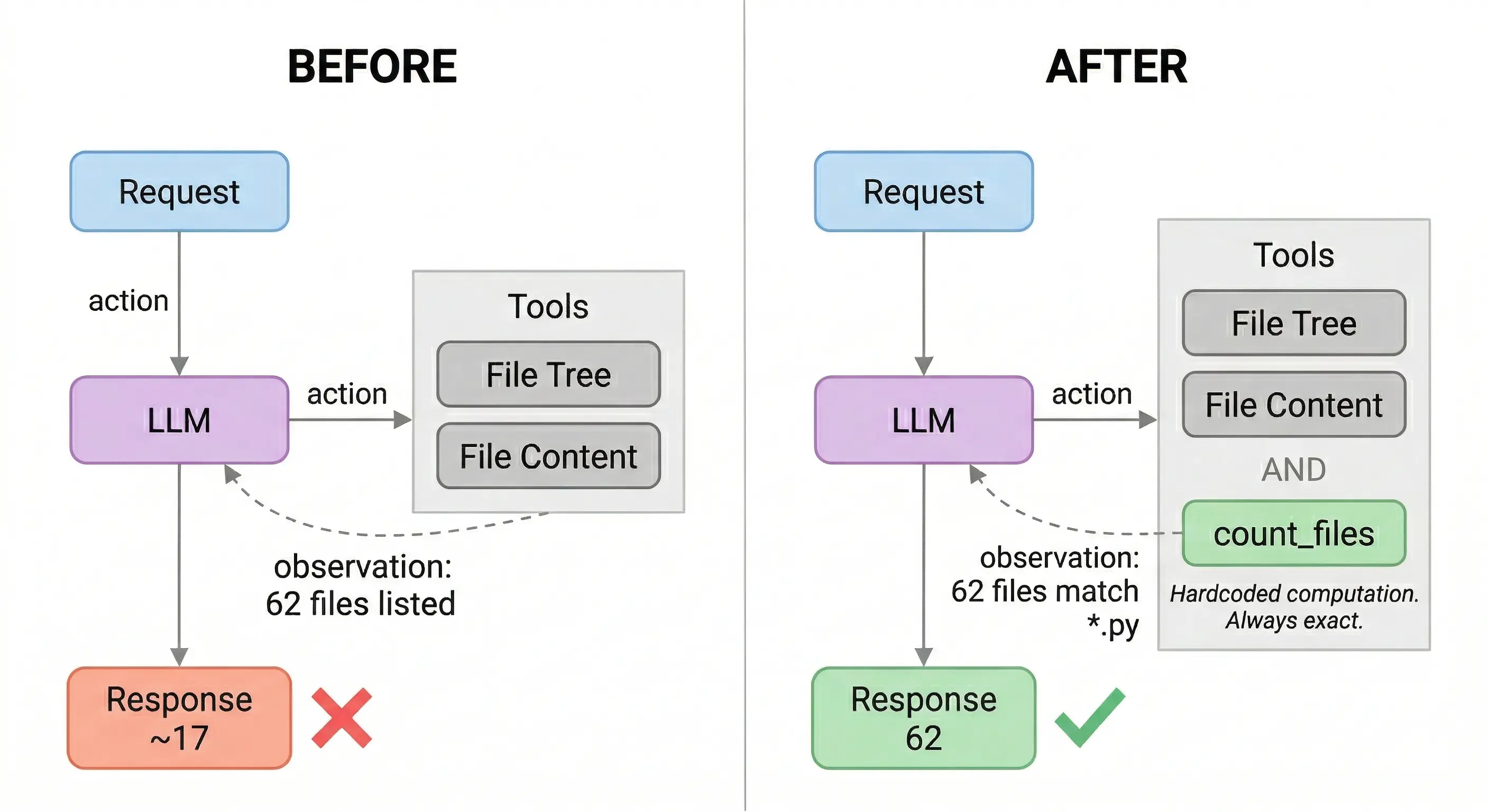
The agent had tools to fetch data. It had no tools to compute on it.
@tool
def count_files(owner: str, repo: str, pattern: str = '*.py') -> str:
"""Count files matching a glob pattern."""
d = _gh(f'/repos/{owner}/{repo}/git/trees/main?recursive=1')
matches = [e for e in d.get('tree', [])
if e['type'] == 'blob' and fnmatch.fnmatch(e['path'], pattern)]
return f'{len(matches)} files match {pattern}'Same counting questions. Same model. Three runs without computation tools, three runs with. Four of the worst:
| Question | Without | With | Truth |
|---|---|---|---|
| Python files | 77, 62, 62 | 62, 62, 62 | 62 |
| Classes in core.py | 9, 8, 9 | 11, 11, 11 | 11 |
| Test functions (all files) | 337, 212, 250 | 372, 372, 372 | 372 |
| Tests in test_options.py | 15, 12, 16 | 80, 80, 80 | 80 |
Counting accuracy: 48% to 100%.
The model didn’t get smarter. It got the right tools. count_files returns 62. Every time. No estimation, no variance. The model reads the number and reports it.
Gemini 3.1 Flash Lite and Gemini 3 Flash. LangGraph. 3 runs per experiment, 5 for consistency. Code: GitHub