Agent Memory Depends on a Prompt Nobody Tests
Two summarizer prompts. Same architecture. One recalled 29% of early facts, the other 86%.
TLDR: When conversations get too long, agents summarize old messages to free up context window. The summarizer is an LLM call with its own prompt. One line added to that summarizer’s prompt changed recall from 29% to 86%.
The decision to summarize old messages is an architectural choice. How they get summarized is a prompt engineering choice. And the prompt matters more. /
The Setup
A LangGraph agent learns 10 facts about a fictional framework across turns 1–10, then gets quizzed on them across turns 11–30. When the conversation gets too long, a summarize node compresses older messages into bullet points, keeping the last 4 verbatim.
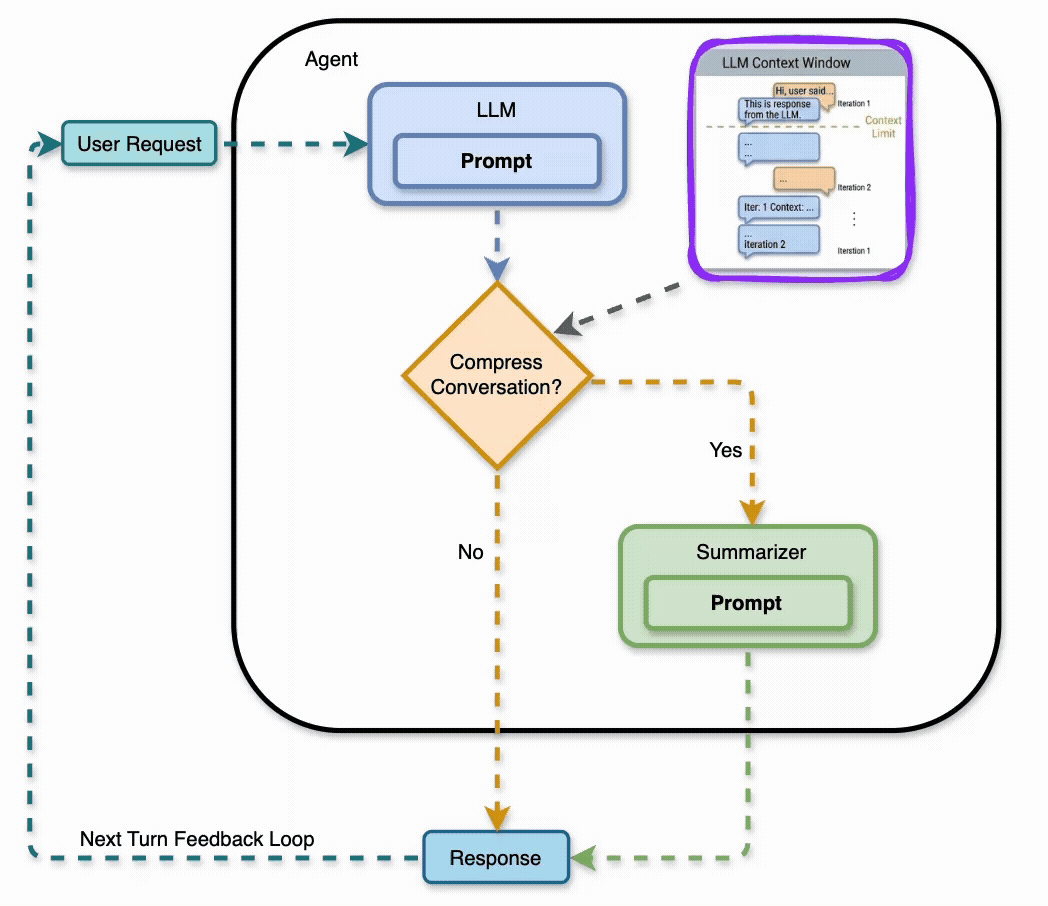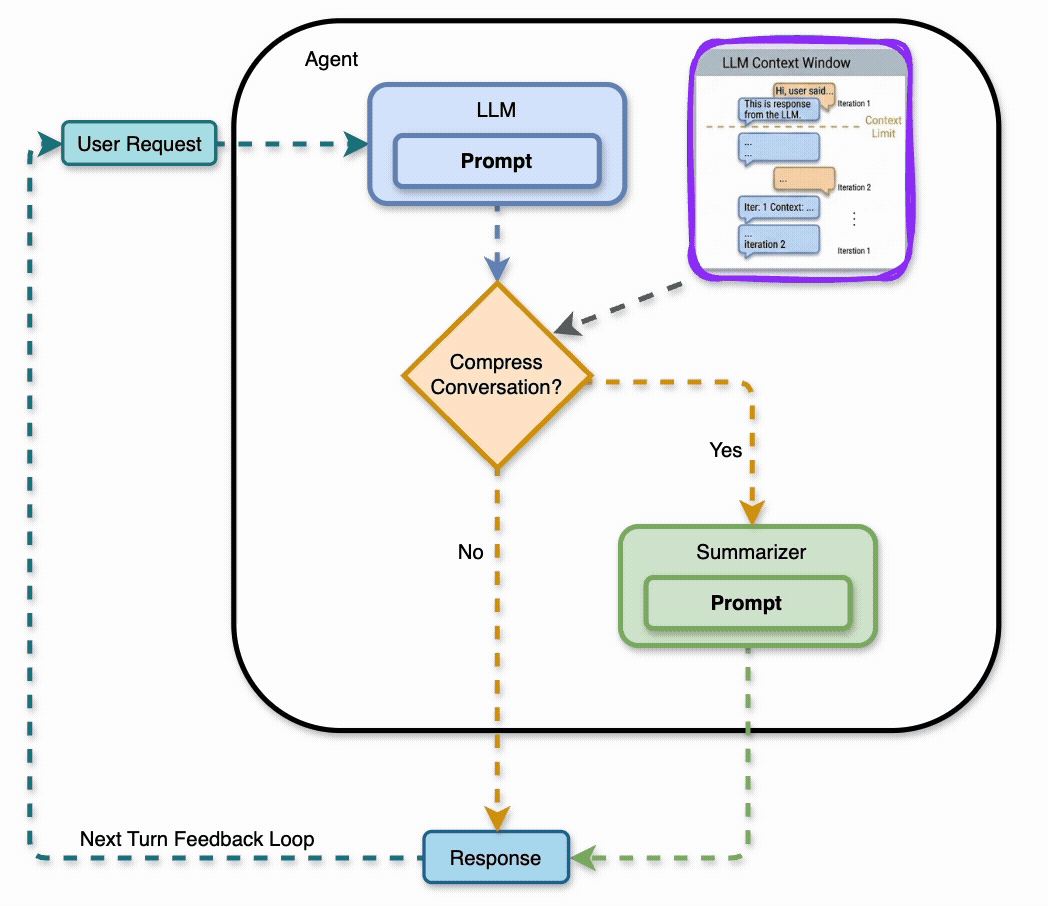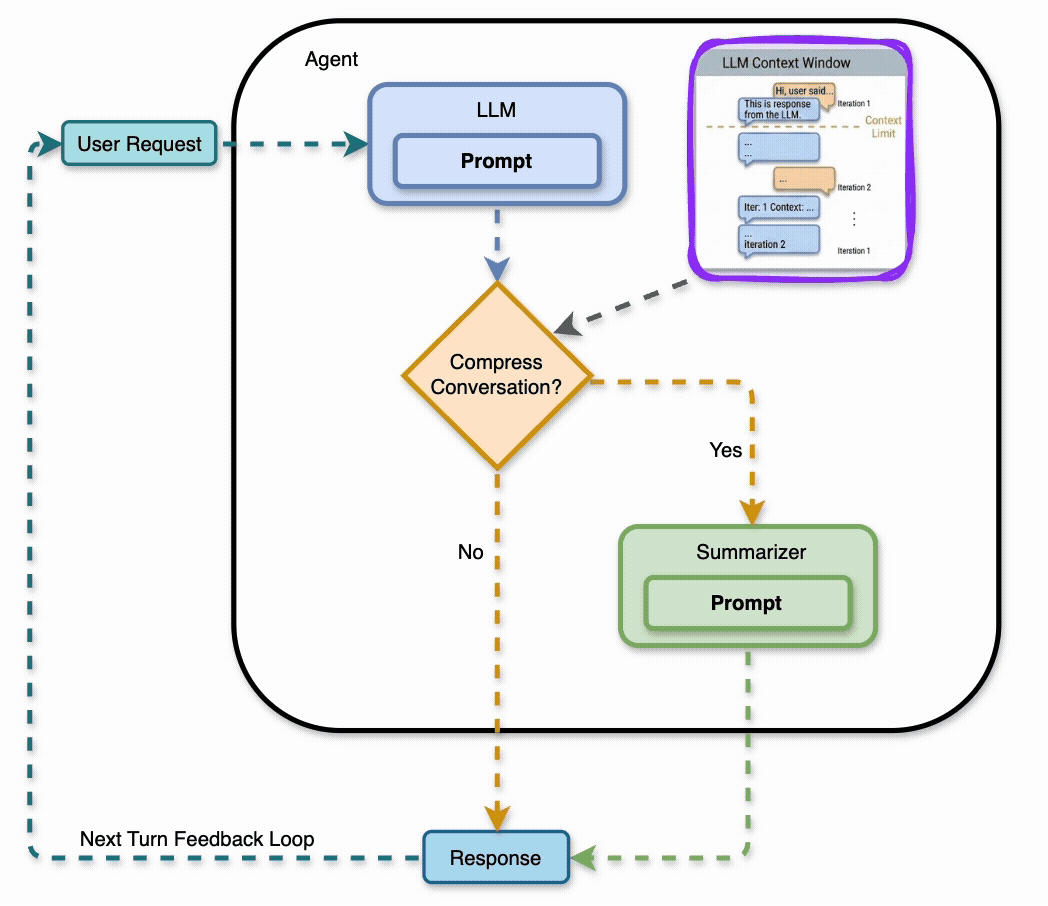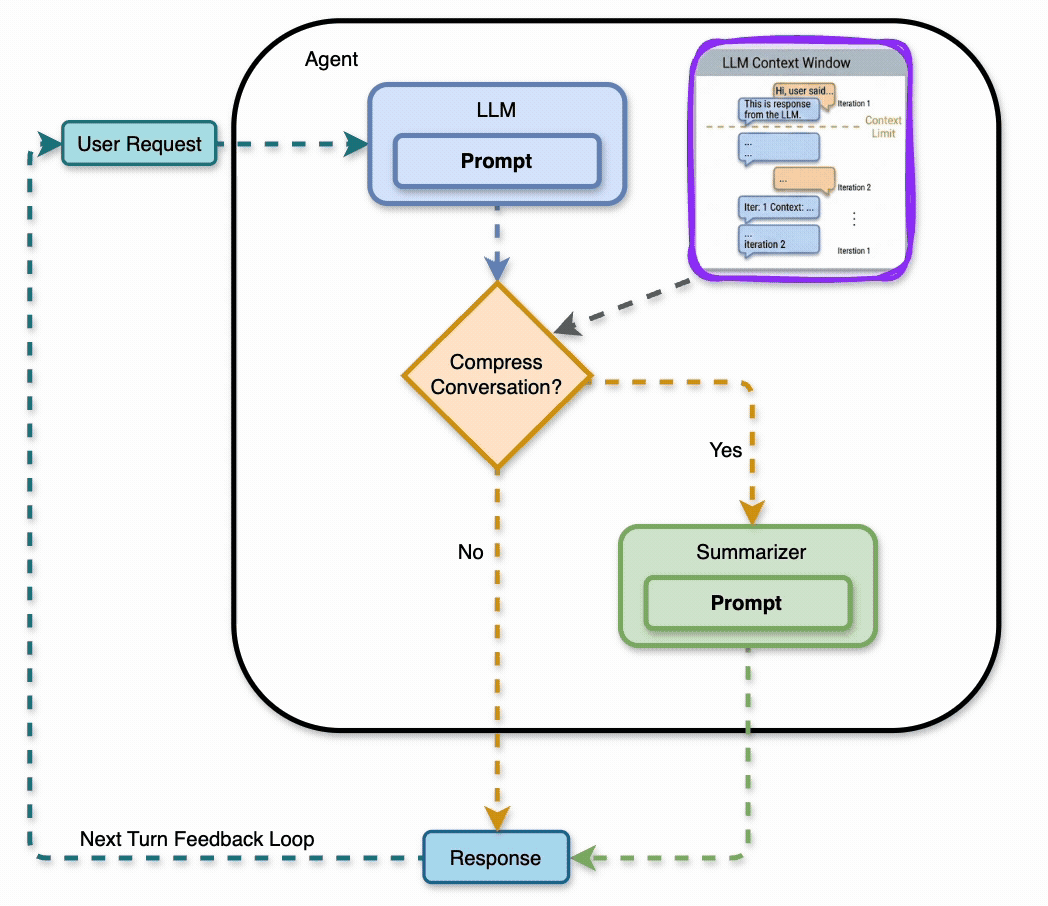
The summary gets re-compressed as the conversation grows. By turn 20, it’s been through multiple compression passes. Each pass risks losing detail.
The Bad Prompt
Compress into bullet points. MAX {budget} tokens.
Keep exact names, numbers, percentages.This produces summaries like:
- AgentForge is written in Go 78.2% and Rust 21.8%
- All agents inherit from CoreAgent
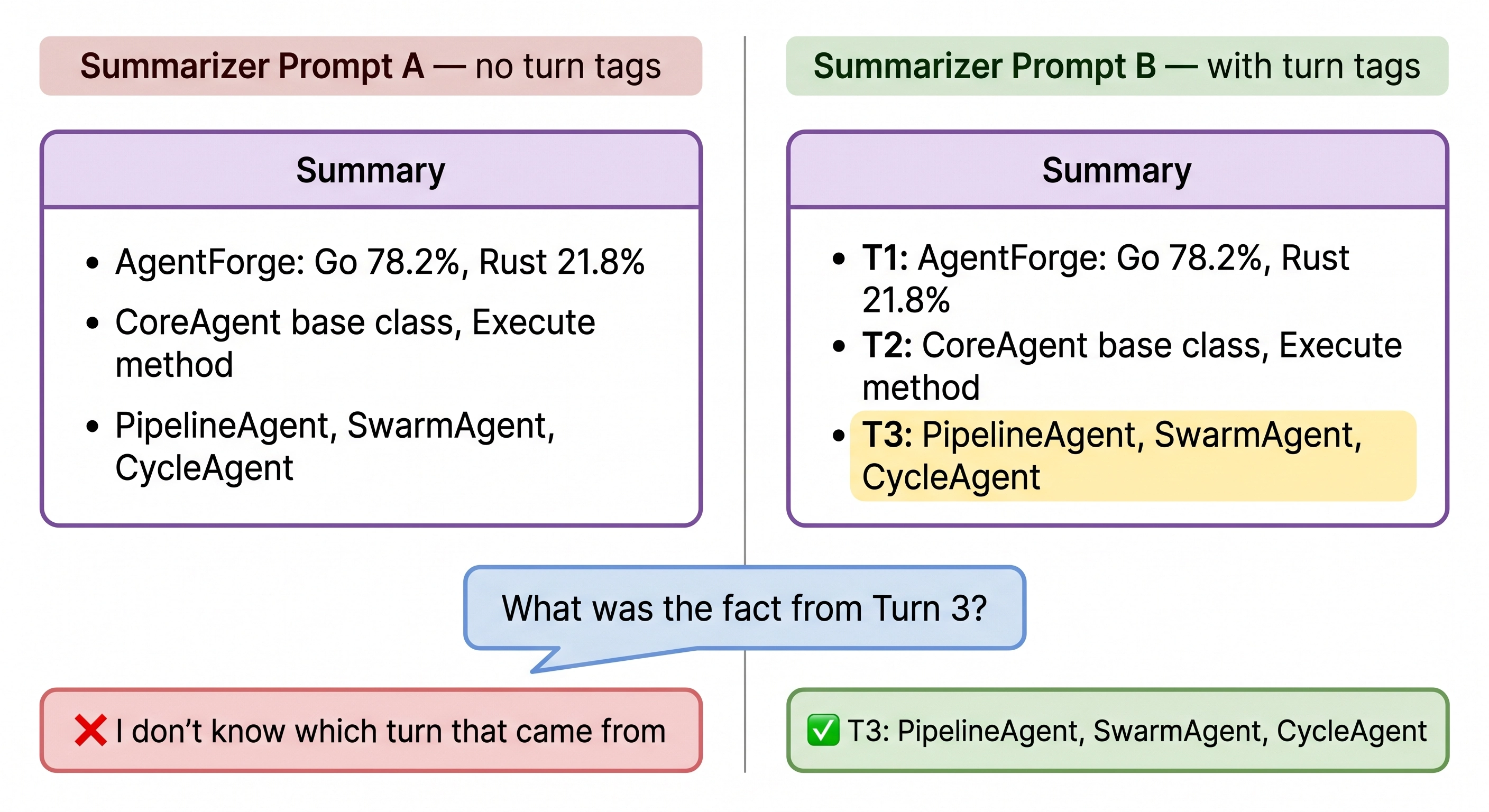
- Three workflow agents: PipelineAgent, SwarmAgent, CycleAgentClean. Accurate. Missing one thing: which fact came from which turn.
When the agent gets asked “what was the exact fact from Turn 3?”, it has the fact (PipelineAgent, SwarmAgent, CycleAgent) but no way to know it was Turn 3’s fact. The summary merged 10 facts into an unlabeled list.
Early fact recall: 29%.
The Fix
One line added to the summarizer prompt:
ALWAYS prefix each bullet with its Turn number: 'T1: ...', 'T3: ...'Full prompt:
You are maintaining a rolling knowledge base.
Merge the prior summary with the new messages below.
Rules:
- ALWAYS prefix each bullet with its Turn number: 'T1: ...', 'T3: ...'
- Keep exact names, numbers, percentages
- One bullet per fact, max 20 words each
- If a fact appears in both prior summary and new messages, keep the more detailed version
- MAX {budget} tokens totalNow the summary looks like:
- T1: Go 78.2%, Rust 21.8%, 4,312 stars, 1,847 commits
- T2: CoreAgent base class, Execute(ctx RunContext) method
- T3: PipelineAgent, SwarmAgent, CycleAgent (Halt=true stops)Same facts. Same token count. Each bullet tagged with its turn.
Results
| Metric | Bad Prompt | Good Prompt |
|---|---|---|
| Overall Accuracy | 0.60 | 0.83 |
| Recent facts | 0.50 | 0.83 |
| Mid-range recall | 0.43 | 0.57 |
| Early fact recall | 0.29 | 0.86 |
Same architecture. Same model. One line different.
Early fact recall: 0.29 to 0.86. The gap exists everywhere, but it’s widest on early facts those only survive inside the summary. That’s where the prompt matters most.
The Summarizer Is a Hidden Prompt
Any strategy that uses an LLM internally has a prompt that shapes what survives. The architecture is the easy part. The prompt inside it is where the performance lives.
If your agent is losing facts it shouldn’t be, check the summarizer’s prompt before rethinking the pipeline. The compression might be fine. The instructions inside it might not be.
Gemini 2.5 Flash Lite. LangGraph 1.1.6. 5 runs per experiment. 30-turn task with fictional AgentForge facts. Code: GitHub